Fivetran
The Fivetran integration synchronizes your Fivetran connection metadata into the lineage graph.
Web App
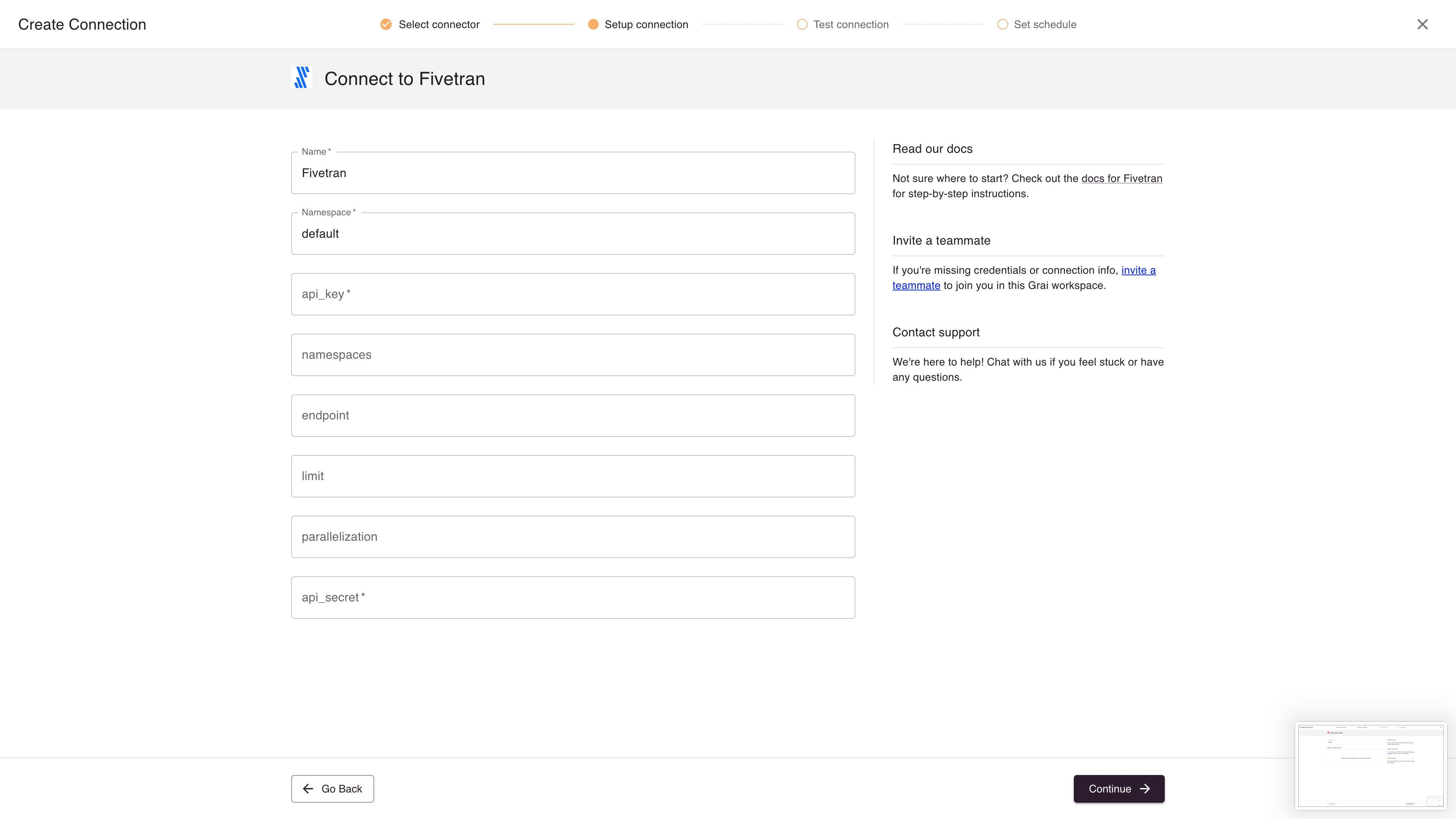
Fields
| Field | Value | Example |
|---|---|---|
| source | The name of the source, see sources | my-source |
| Name | Name for connection | Fivetran |
| Namespace | Namespace for the connection, see namespace | default |
| api_key | Fivetran api key, see api key | |
| namespaces | Optional | |
| endpoint | Optional endpoint if self-hosting fivetran | |
| limit | Limit the number of rows returned, optional | 10000 |
| parallelization | Run integration in parallel, optional | 10 |
| api_secret | Fivetran api secret, see api key |
ApiKey
Follow https://fivetran.com/docs/rest-api/getting-started (opens in a new tab) to generate an api key.
Python Library
The Fivetran integration can be run as a standalone python library to extract data lineage from the Fivetran api.
The library is available via pip
pip install grai_source_fivetranMore information about the API is available here.
Examples
The library is split into a few distinct functions but if you only wish to extract nodes/edges from Fivetran you can do so as follows:
from grai_source_fivetran import FivetranIntegration
from grai_schemas.v1.source import SourceV1
source = SourceV1(name="my-source", type="my-type")
fivetran_credentials = {
"api_key": "my-api-key",
"api_secret": "my-api-secret"
}
integration = FivetranIntegration(source=source, default_namespace="fivetran", **fivetran_credentials)
nodes, edges = integration.get_nodes_and_edges()In this case, we are putting all nodes and edges produced by Fivetran in a single namespace.
In practice you usually don't want to do this because it will result in overlapping id's.
For example, a fivetran connection copying data from a source table my_table to a destination table my_table will
result in two nodes with the same id.
To avoid this, you can pass a namespaces parameter to the FivetranIntegration constructor which will map Fivetran
connection id's to source and destination grai namespaces.
namespaces = {<fivetran_connection_id>: {
'source': [source_namespace],
'destination': [destination_namespace]}
}
integration = FivetranIntegration(source=source, namespaces=namespaces, **fivetran_credentials)In order to build the namespaces you'll need to know the fivetran_connection_id for each connection.
You can find these in the Fivetran dashboard or using Grai
integration = FivetranIntegration(source=source, default_namespace="fivetran", **fivetran_credentials)
integration.connector.connectors.keys()Remember, Fivetran connectors sync data from a source (like Postgres) to a destination (like Snowflake).
In order for the lineage graph to be complete, you'll need to specify the namespace you've chosen in Grai for each.
For a single a Fivetran connector with with the id crunchy-muffin syncing data from a MySQL database you had added to Grai under the prod namespace
to a Snowflake database you had added to Grai under the warehouse namespace the namespaces would look like this:
namespaces = {
"crunchy-muffin": {
"source": "prod",
"destination": "warehouse"
}
}